Материалы по тегу: intel max
|
01.09.2023 [14:05], Сергей Карасёв
В Лос-Аламосской лаборатории запущен суперкомпьютер Crossroads на базе Intel Xeon Sapphire RapidsЛос-Аламосская национальная лаборатория (LANL) Министерства энергетики США сообщила о запуске суперкомпьютера Crossroads — первого в мире крупного вычислительного комплекса, полагающегося исключительно на процессоры Intel Xeon Sapphire Rapids, в том числе с HBM-памятью. Система будет применяться для решения сложных научных задач, связанных с ядерным арсеналом США. О создании 165-Пфлопс машины впервые было объявлено в конце 2020 года, а первая фаза установки Crossroads была завершена в октябре 2022 года. Тогда говорилось, что по FP64-производительности новый суперкомпьютер превзойдёт существующую систему LANL Trinity в четыре раза. Отличительной чертой машины является то, что она полагается исключительно на CPU Intel. Как теперь сообщается, в июне оставшееся оборудование, включая компоненты системы жидкостного охлаждения, было доставлено в Стратегический вычислительный комплекс (Strategic Computing Complex), где размещены HPC-системы LANL. После этого специалисты HPE произвели монтаж узлов и обеспечили подключение Crossroads к сети лаборатории. В настоящее время проводится первоначальная диагностика систем Crossroads. Суперкомпьютер станет доступен пользователям нынешней осенью. 
Источник изображения: LANL Утверждается, что Crossroads обеспечит в четыре–восемь раз более высокую производительность по сравнению с Trinity при решении сложных задач моделирования. Но точные показатели быстродействия пока не раскрываются. Известно, что в состав суперкомпьютера входят узлы с HBM-версией Sapphire Rapids (Intel Max), а также подсистема хранения данных типа All-Flash.
25.07.2023 [15:09], Сергей Карасёв
TACC получит 10-Пфлопс суперкомпьютер Stampede3 на базе Intel Max и 400G Omni-PathТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) анонсировал НРС-комплекс Stampede3, на создание которого Национальный научный фонд (NSF) выделил $10 млн. Новый суперкомпьютер станет последователем систем Stampede (2012 год) и Stampede2 (2017 год). В состав Stampede3 войдут 560 узлов на базе двух 56-ядерных процессоров Intel Xeon Max с 64 Гбайт встроенной памяти HBM2e. Это в сумме даст почти 63 тыс. вычислительных ядер общего назначения, а пиковая производительность составит около 4 Пфлопс (FP64). Кроме того, Stampede3 будет включать в себя 10 серверов Dell PowerEdge XE9640, содержащих 40 ускорителей Intel Max (Ponte Vecchio). Примечательно, что новые CPU-узлы не будут оснащаться DDR5. Если памяти на ядро для некоторых задач будет не хватать, то их перенесут на другие узлы — в составе Stampede3 будут повторно задействованы 224 узла Stampede2 с двумя 40-ядерными процессорами Intel Xeon Ice Lake-SP и 256 Гбайт RAM. Более того, к ним присоединятся 1064 узла системы Stampede2, каждый из которых содержит два чипа Intel Xeon Skylake-SP с 24 ядрами и 192 Гбайт памяти. 
Источник изображения: TACC Фактически TACC теперь полностью избавилась от Xeon Phi и сохранила часть узлов от старых систем в новой машине, а некоторые пустила на создание склада запчастей. В общей сложности Stampede3 объединит 1858 вычислительных узлов, содержащих более 140 000 процессорных ядер и свыше 330 Тбайт памяти. Пиковая производительность составит почти 10 Пфлопс. Ещё одна интересная особенность суперкомпьютера — использование новейшего 400-Гбит/с интерконнекта Omni-Path. Точнее, часть старых систем останется с 100G Omni-Path, хотя коммутаторы будут обновлены. То есть Cornelis Networks сдержала обещание, пропустив поколение OPA-200 и сразу перейдя к созданию OPA-400. Кроме того, суперкомпьютер получит полностью новое All-Flash (QLC) хранилище VAST вместимостью 13 Пбайт и скоростью доступа 450 Гбайт/с, тоже на базе серверов Dell. СХД придёт на замену Lustre-хранилищу. Узлы Stampede3 будут поставлены осенью нынешнего года, а на полную мощность суперкомпьютер заработает в начале 2024-го. Комплекс станет частью вычислительной экосистемы ACCESS Национального научного фонда.
09.07.2023 [18:07], Алексей Степин
AMX и HBM2e обеспечивают Intel Xeon Max серьёзное преимущество в некоторых ИИ-нагрузкахВ Сети продолжают появляться новые данные о производительности процессоров Intel Xeon Max с набортной памятью HBM2e объёмом 64 Гбайт. На этот раз ресурс Phoronix опубликовал сравнительные результаты тестирования двухпроцессорных платформ Xeon Max 9480 в сравнении с решениями AMD EPYC 9004. Не секрет, что процессоры Intel Xeon существенно уступают по максимальному количеству ядер решениям AMD EPYC уже давно — даже у обычных Sapphire Rapids их не более 60, а у Xeon Max и вовсе в максимальной конфигурации лишь 56 ядер. Однако Intel в этом поколении старается взять своё не числом, а уменьем — поддержкой новых расширений, в частности, AMX. В новом тестировании ИИ-нагрузок, опубликованном Phoronix, приняла участие двухпроцессорная система на базе Xeon Max 9480 в различных режимах (только с HBM, без HBM или с HBM в режиме кеширования), а также две двухпроцессорные системы AMD на базе EPYC 9554 (128 ядер) и EPYC 9654 (192 ядра). В качестве бенчмарков были выбраны фреймворки OpenVINO (оптимизирован для AMX) и ONNX (без глубокой оптимизации). 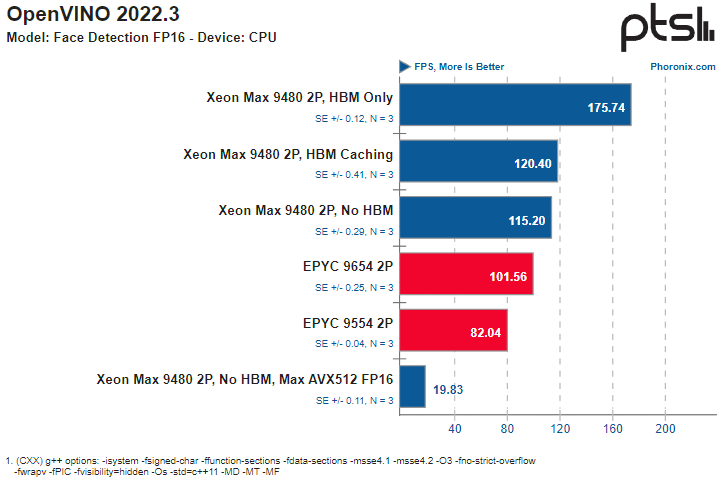
Источник здесь и далее: Phoronix В ряде тестов OpenVINO наивысший результат продемонстрирован платформой Xeon Max в режиме HBM Only, несмотря на огромное отставание по количеству ядер. И худший же результат принадлежит тоже Xeon Max, но при отключении HBM и переходу к AVX512 FP16 без использования AMX. 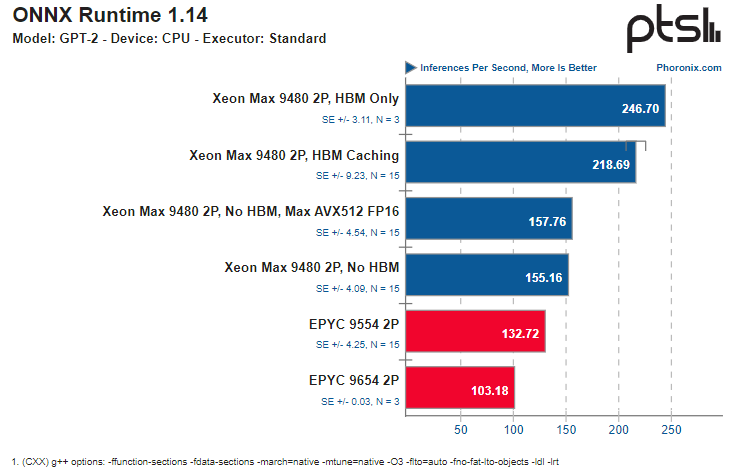 Иногда AMD удаётся взять реванш благодаря количеству ядер, причём отключение HBM2e не всегда спасает «красных» — с помощью AMX «синие» продолжают довольно уверенно лидировать во многих тестах. Тестирование в ONNX Runtime 1.14 на базе языковой модели GPT-2 также показало, что Xeon Max опережают EPYC Genoa — но серьёзный выигрыш достигается только при использовании HBM. 
Даже без HBM поддержка AMX помогает Xeon Max показать достойный результат Подход Intel демонстрирует отличные результаты: в ряде случаев переход от AVX512 к AMX позволяет поднять производительность в 2,5 раза. Благодаря HBM2e можно получить ещё около 25 %, а в целом прирост может достигать 3,13 раз. Впрочем, у AMD в запасе есть EPYC Genoa-X с огромным кешем 3D V-Cache, так что стоит подождать следующего раунда этой битвы.
29.06.2023 [18:46], Алексей Степин
Опубликованы результаты тестов Intel Xeon Max: набортная HBM-память даёт заметное преимущество в ИИ- и HPC-нагрузкахПроцессоры Intel серии Xeon Max отличаются от своих обычных, «не максимальных» собратьев наличием интегрированной памяти HBM2e объёмом 64 Гбайт. Что же это даёт им на практике? Этот вопрос исследовал ресурс Phoronix — им в руки новейшие двухсокетные системы Supermicro Hyper SuperServer SYS-221H-TNR с чипами Xeon Max 9468 и 9480. Напомним, Intel Xeon Max отличается от своих обычных собратьев серии Sapphire Rapids наличием 64 Гбайт HBM2e на борту, причём объём одинаков для всех моделей, хотя количество ядер может варьироваться от 32 до 56. Процессоры Xeon Max были протестированы в трёх режимах: только с памятью HBM (без DDR5), с HBM в качестве кеша для 512 Гбайт DDR5, а также в «плоском» режиме, но без отдачи HBM какому-либо процессу, то есть фактически только с DDR5. 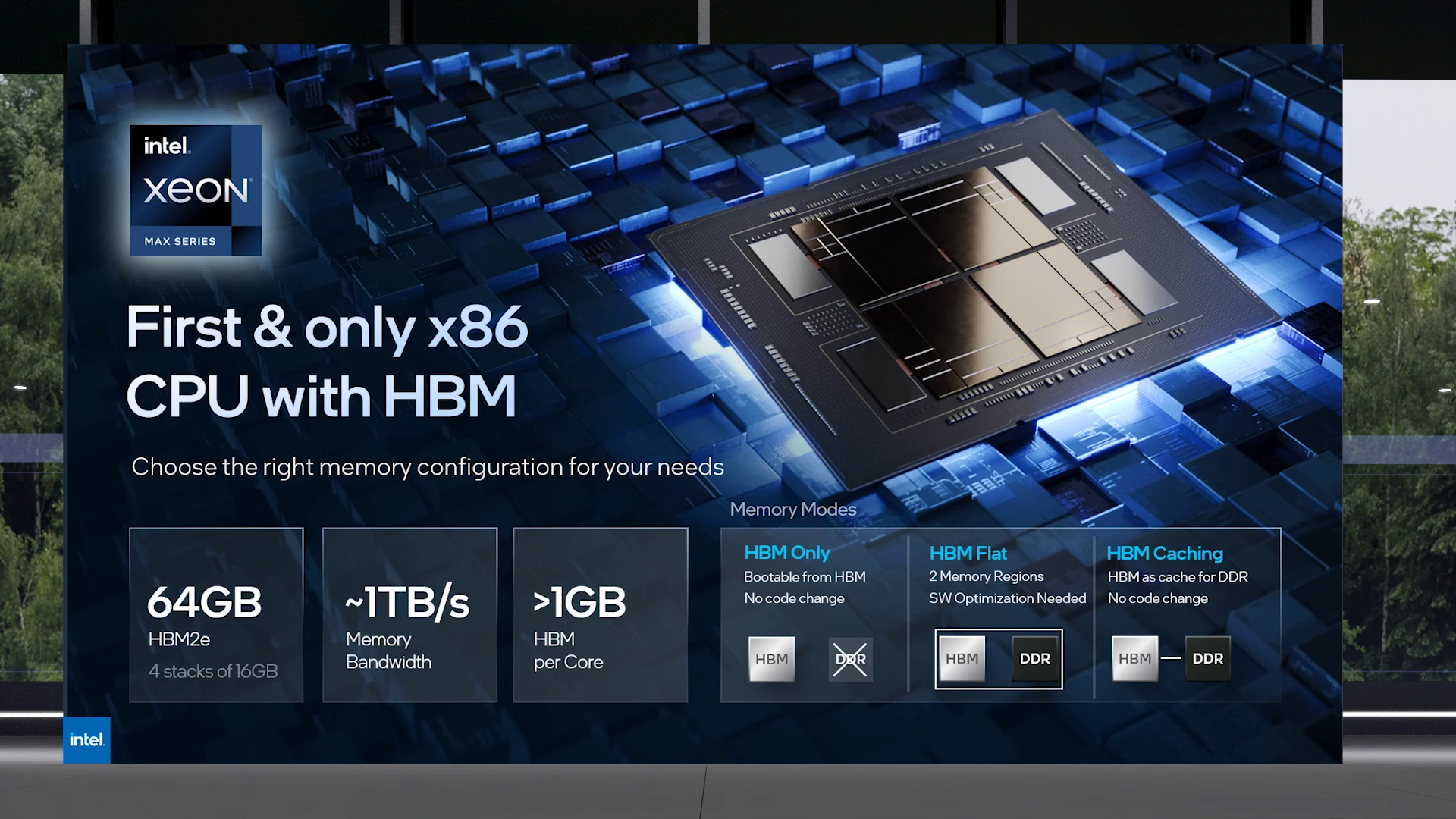
Изображение: Intel Тесты показали, что два первых режима действительно могут обеспечить преимущество в некоторых сценариях нагрузки. Результаты получились вполне закономерными: там, где сравнительно небольшого объёма HBM2e достаточно, режим HBM Only оказывается самым быстрым из-за высокой пропускной способности и отсутствия необходимости как-то синхронизировать работу с DDR5. 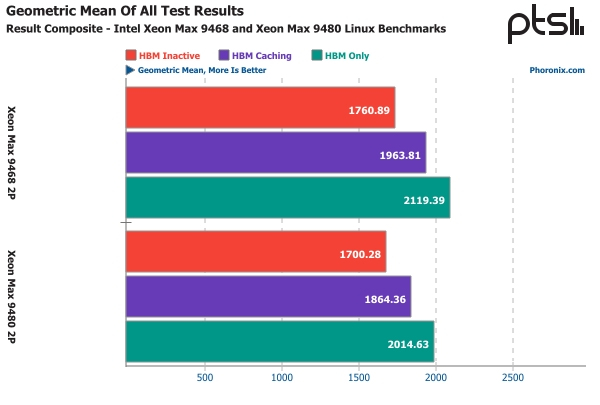
Источник: Phoronix Однако режим кеширования тоже обеспечивает выигрыш, хотя в ряде нагрузок, таких как OpenFOAM, он не такой большой. В ИИ-сценариях, в частности, в тестах OpenVINO, разница меньше, а иногда отключение HBM2e и вовсе позволяет добиться чуть лучшей производительности, особенно на системе с Xeon Max 9480, где на каждое ядро приходится меньше памяти. Но в других тестах, таких как PETSc и Stress-NG, использование HBM2e может дать огромный прирост производительности, который глупо было бы игнорировать.  В целом, можно уверенно заявлять, что в среднем, прирост производительности при HBM-кешировании составляет 10–11 %, а при отказе от DDR5 к этому значению можно добавить ещё около 8 %. Также очевидно, что потребление системы в таком режиме заметно ниже, поскольку не требуется питание для модулей DDR5. В целом можно говорить о 18–20 % превосходства на широком спектре нагрузок, сообщает Phoronix.
23.06.2023 [01:42], Владимир Мироненко
Завершён монтаж суперкомпьютера Aurora на базе Intel Max: 2 Эфлопс, более 20 Тбайт HBM2e и 220-Пбайт хранилищеАргоннская национальная лаборатория (ANL) Министерства энергетики США и Intel объявили о завершении установки всех 10 624 блейд-серверов суперкомпьютера Aurora. Система, как сообщается, обеспечит пиковую теоретическую FP64-производительность более 2 Эфлопс, используя массив из десятков тысяч процессоров Intel Xeon Max, а также ускорителей Data Center GPU Max (Ponte Vecchio). 
Фото: Intel Система будет использоваться для самых разных рабочих нагрузок, от моделирования ядерного синтеза до расчётов по аэродинамике и медицинских исследований. Для Intel (в отличие от AMD) это будет первая в истории машина экзафлопсного класса. Ожидается, что Aurora может возглавить ноябрьский рейтинг TOP500. Впрочем, её может опередить El Capitan или неожиданно появившаяся китайская система. 
Фото: Intel Суперкомпьютер Aurora оснащён 21 248 CPU с более чем 1,1 млн ядер и 63 744 ускорителями, которые будут обслуживать рабочие нагрузки в области ИИ и высокопроизводительных вычислений (HPC). Процессоры Aurora имеют 1,36 Пбайт встроенной памяти HBM2E и дополнены 19,9 Пбайт DDR5, ещё 8,16 Пбайт памяти HBM2E входят в состав ускорителей Ponte Vecchio. Машина состоит из 166 стоек (66 «лезвий» в каждой) в восьми рядах. DAOS-хранилище Aurora содержит 1024 All-Flash узла общей ёмкостью 220 Пбайт и пропускной способностью 31 Тбайт/с. 
Фото: Intel На данный момент ANL не сообщила официальные данные об энергопотреблении Aurora и её подсистемы хранения. Aurora создана на базе платформы HPE Cray Shasta с интерконнектом HPE Slingshot. Хотя блейд-серверы Aurora уже установлены, суперкомпьютеру предстоит пройти ряд приёмочных испытаний, что является обычной процедурой для таких систем. А пока он будет использоваться для обучения крупномасштабных научных моделей для генеративного ИИ.
07.06.2023 [15:28], Сергей Карасёв
HPE создаст новую HPC-систему c процессорами Intel Max для Университета штата Нью-Йорк в Стони-БрукеУниверситет штата Нью-Йорк в Стони-Бруке анонсировал проект нового НРС-комплекса, который планируется использовать при проведении исследований в таких областях, как инженерия, физика, социальные и биологические науки. Созданием суперкомпьютера займутся специалисты компании HPE. В основу платформы лягут серверы HPE ProLiant DL360 Gen11 на процессорах Intel Xeon Sapphire Rapids. В том числе будут задействованы узлы на базе Intel Xeon Max. Утверждается, что применение этих решений позволит повысить плотность компоновки оборудования и уменьшить площадь дата-центра — в том числе благодаря возможности развёртывания СЖО. Помимо НРЕ и Intel, в проекте принимает участие системный интегратор ComnetCo. Эта фирма и раньше сотрудничала с Университетом штата Нью-Йорк в Стони-Бруке; кроме того, она имеет опыт взаимодействия с исследовательскими организациями и государственными заказчиками. Управление НРС-платформой возьмут на себя Институт передовых вычислительных наук (IACS) и Отдел информационных технологий (DoIT) в составе университета. 
Отмечается, что Университет штата Нью-Йорк в Стони-Бруке станет первым академическим учреждением в США, развернувшим суперкомпьютерную платформу с процессорами Xeon Max на серверах HPE ProLiant. Доступ к ресурсам платформы планируется предоставлять в масштабах всего кампуса. Сведений о производительности системы на данный момент нет.
23.05.2023 [15:26], Сергей Карасёв
Intel рассказала о суперкомпьютере Aurora производительностью более 2 ЭфлопсКорпорация Intel в ходе конференции ISC 2023, как сообщает AnandTech, поделилась информацией о проекте Aurora по созданию суперкомпьютера с производительностью экзафлопсного уровня. Эта система создаётся для Аргоннской национальной лаборатории Министерства энергетики США. Изначально анонс HPC-комплекса Aurora состоялся ещё в 2015 году с предполагаемым запуском в 2018-м: ожидалось, что машина обеспечит быстродействие на уровне 180 Пфлопс. Однако реализация проекта значительно затянулась, а технические параметры платформы неоднократно менялись. Пока что развёрнуты тестовый кластер Sunspot. Как теперь сообщается, в конечной конфигурации Aurora объединит 10 624 узла, каждый из которых будет включать два процессора Xeon Max и шесть ускорителей Ponte Vecchio. Таким образом, общее количество CPU будет достигать 21 248, число GPU — 63 744. Быстродействие FP64, как и было заявлено ранее, превысит 2 Эфлопс. 
Источник изображений: Intel (via AnandTech) Каждый процессор оперирует 64 Гбайт памяти HBM, ускоритель — 128 Гбайт. В сумме это даёт соответственно 1,36 Пбайт и 8,16 Пбайт памяти HBM с пиковой пропускной способностью 30,5 Пбайт/с и 208,9 Пбайт/с. В дополнение система сможет использовать 10,9 Пбайт памяти DDR5 с пропускной способностью до 5,95 Пбайт/с. Вместимость подсистемы хранения данных составит 230 Пбайт со скоростью работы до 31 Тбайт/с.  На сегодняшний день Intel поставила более 10 тыс. «лезвий» для Aurora, а это означает, что практически все узлы готовы к окончательному монтажу. Ввод суперкомпьютера в эксплуатацию намечен на текущий год. Для НРС-платформы готовится специализированная научная модель генеративного ИИ — Generative AI for Science, насчитывающая около 1 трлн параметров. Применять Aurora планируется для решения наиболее ресурсоёмких задач в различных областях.
05.05.2023 [13:16], Сергей Карасёв
Supermicro представила первые коммерческие серверы на базе ускорителей Intel MaxКомпания Supermicro анонсировала стоечные системы SYS-421GE-TNRT и SYS-821PV-TNR — первые в отрасли коммерческие серверы, оборудованные ускорителями Intel Max (Ponte Vecchio). Аппаратной основой представленных решений служат процессоры Intel Xeon Sapphire Rapids. Обе новинки рассчитаны на установку двух чипов в исполнении Socket E (LGA-4677). Поддерживается до 8 Тбайт оперативной памяти DDR5-4800 в виде 32 модулей ёмкостью 256 Гбайт каждый. Есть 24 отсека во фронтальной части для SFF-накопителей U.2/SATA/SAS. Модель SYS-421GE-TNRT допускает установку восьми ускорителей Data Center GPU Max 1100 с 48 Гбайт памяти HBM2 каждый. Кроме того, предусмотрены два коннектора для M.2 NVMe SSD. Система оборудована двумя сетевыми портами 10GbE (Intel X710-AT2), выделенным сетевым портом управления, разъёмом D-Sub и последовательным портом. 
Источник изображений: Supermicro Для CPU может применяться воздушное или жидкостное охлаждение. Сервер наделён восемью вентиляторами повышенной надёжности. Устройство выполнено в форм-факторе 4U. Питание обеспечивают четыре блока мощностью 2700 Вт стандарта 80 PLUS Titanium. Диапазон рабочих температур — от +10 до +35 °C. 
Сервер SYS-821PV-TNR, в свою очередь, может нести на борту до восьми ускорителей Data Center GPU Max 1550 OAM со 128 Гбайт памяти HBM2 каждый. Для CPU и GPU может быть задействовано воздушное или жидкостное охлаждение. Заявленная производительность достигает 6,7 Пфлопс FP16/BF16. Другие характеристики будут раскрыты позднее.
25.04.2023 [20:01], Алексей Степин
Как Aurora, но поменьше: запущен тренировочный суперкомпьютер Sunspot на чипах Intel MaxОдин из самых масштабных проектов в области высокопроизводительных вычислений (HPC), 2-Эфлопс суперкомпьютер Aurora, который планирует вскоре ввести в строй Аргоннская национальная лаборатория (ANL), получил ещё одну тестовую платформу. Новый мини-кластер Sunspot, включающий в себя две стойки будущей машины, является прекрасным полигоном для отладки ПО. Aurora будет состоять из более чем 10 тыс. вычислительных узлов, а Sunspot включает в себя 128 узлов, каждый из которых, впрочем, имеет весьма серьёзную конфигурацию. На борту такой узел несёт пару процессоров Intel Xeon Max (Sapphire Rapids + 64 Гбайт HBM2e), а также шесть ускорителей Intel Max Series (Ponte Vecchio). Sunspot использует в качестве интерконнекта фирменную сеть HPE/Cray Slingshot последнего поколения. 
Источник: Argonne Leadership Computing Facility Как считает глава Argonne Leadership Computing Facility (ALCF), полная идентичность архитектур позволит разработчикам оптимизировать код для максимального использования всех возможностей Sapphire Rapids и Ponte Vecchio. Ранее тестовыми платформами служили кластеры Iris, Arcticus, Florentia самой Аргоннской лаборатории, а также Borealis, принадлежащий Intel. Система Sunspot была запущена ещё в декабре, с тех пор к ней получили доступ более 180 исследователей из 20 команд разработчиков в рамках программ Aurora Early Science Program (ESP) и Exascale Computing Project (ECP). 
Процесс сборки Aurora идёт полным ходом Отмечается, что достигнутые на «железе» Intel Max результаты внушают оптимизм. В ряде научно-технических задач прирост производительности от перехода на ускорители Intel составил от 20 до 70 %, а в разрабатываемом аргоннцами Hardware/Hybrid Accelerated Cosmology Code выигрыш достиг 2,6 раз. Ожидается, что дальнейшая более тонкая оптимизация позволит улучшить результаты. Интересно, что даже после запуска Aurora система Sunspot демонтирована не будет, а станет, как и все предыдущие тестовые платформы ALCF, общедоступным «полигоном для новичков».
11.01.2023 [03:00], Игорь Осколков
Асимметричный ответ: Intel официально представила процессоры Xeon Sapphire RapidsIntel официально представила серверные процессоры Xeon семейства Sapphire Rapids (SPR), выход которых изрядно задержался, а также ускорители ранее известные как Ponte Vecchio и теперь объединённые вместе с HBM-версиями SPR в отдельную HPC-серию Max. В этом поколении Intel не смогла догнать AMD EPYC Genoa по числу ядер, числу каналов памяти и линий PCIe, но заготовила ассиметричный, хотя и очень странно реализованный ответ. Всего представлено 52 модели с числом P-ядер от 8 до 60 и с TDP от 125 до 350 Вт. По числу ядер это существенный апгрейд по сравнению с Ice Lake-SP (до 40 ядер), да и IPC вырос у Golden Cove на 15 % в сравнении с Sunny Cove. Но это существенный проигрыш в сравнении с Genoa (до 96 ядер), особенно если учитывать их максимальный TDP в 360 Вт (cTDP до 400 Вт). Правда, у Sapphire Rapids есть ещё и экономичный режим работы, в котором энергопотребление снижается на 20 %, а производительность для некоторых нагрузок — всего на 5 %. 
Изображения: Intel Sapphire Rapids предлагают 8 каналов памяти DDR5-4800 (1DPC) и DDR5-4400 (2DPC). 2DPC у Genoa пока что нет. Кроме того, контроллеры поддерживают и модули Optane PMem 300 (Crow Pass), но с учётом того, что производство 3D XPoint прекращено, достаться они могут не всем (впрочем, не всем они и нужны). Ну а маленькая серия Max также включает 64 Гбайт набортной HBM2e-памяти (1,2 Тбайт/с). Остались и отличия в максимальном объёме SGX-анклавов в зависимости от модели CPU. 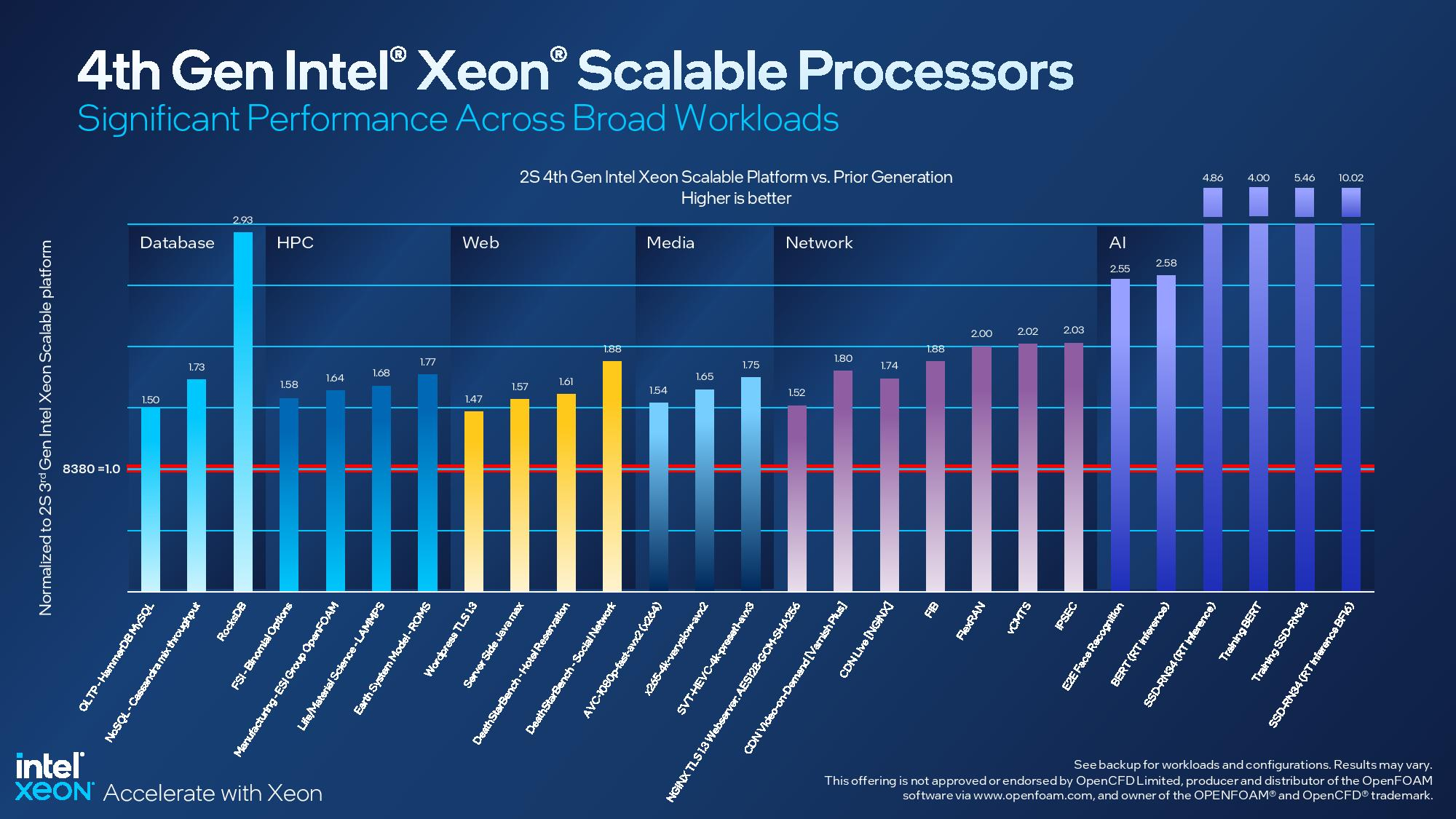 Однако по числу ядер на узел всё равно лидирует Intel. Если AMD поддерживает только 2S-конфигурации, то Intel снова предлагает и 4S, и 8S (а с момента выхода Cooper Lake-SP прошло немало времени) — на процессор доступно до 4 линий UPI 2.0 (16 ГТ/с в сравнении с 11,2 ГТ/с у Ice Lake-SP). В 2S-платформах Sapphire Rapids также формально обгоняет Genoa по числу линий PCIe 5.0, которых тут по 80 шт. на сокет. Формально потому, что в случае Genoa при желании всё же можно получить 160 линий, пожертвовав скоростью шины между CPU, но в односокетном варианте EPYC в любом случае интереснее Xeon. 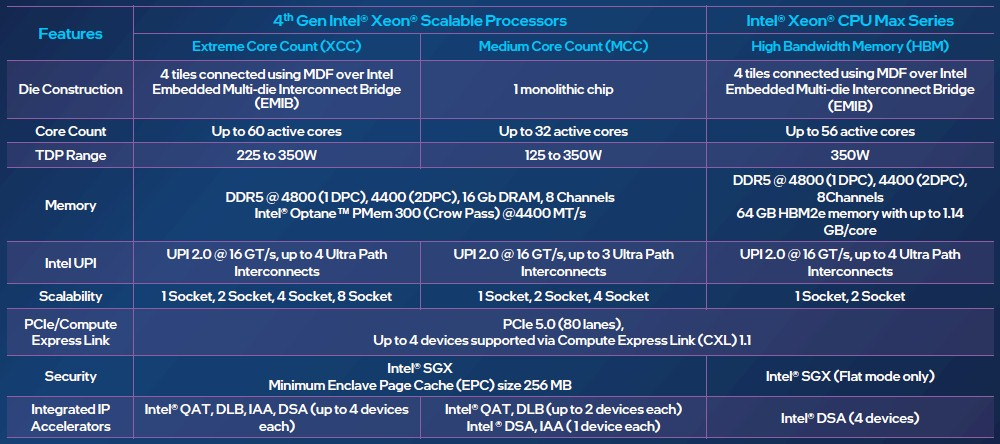 Без нюансов тут не обошлось. Так, при бифуркации до 8 x2 скорость падает до PCIe 4.0. Зато каждый root-комплекс поддерживает CXL 1.1, тогда как у Genoa CXL есть только у половины! Впрочем, поддержка всё равно ограничена 4x CXL-устройствами на CPU. Что ещё более странно, официально заявлена поддержка только устройств Type 1 и Type 2, но не Type 3, хотя последние весьма пригодились бы в ряде конфигураций, где требуется больше относительно недорогой, пусть и несколько более медленной, RAM. 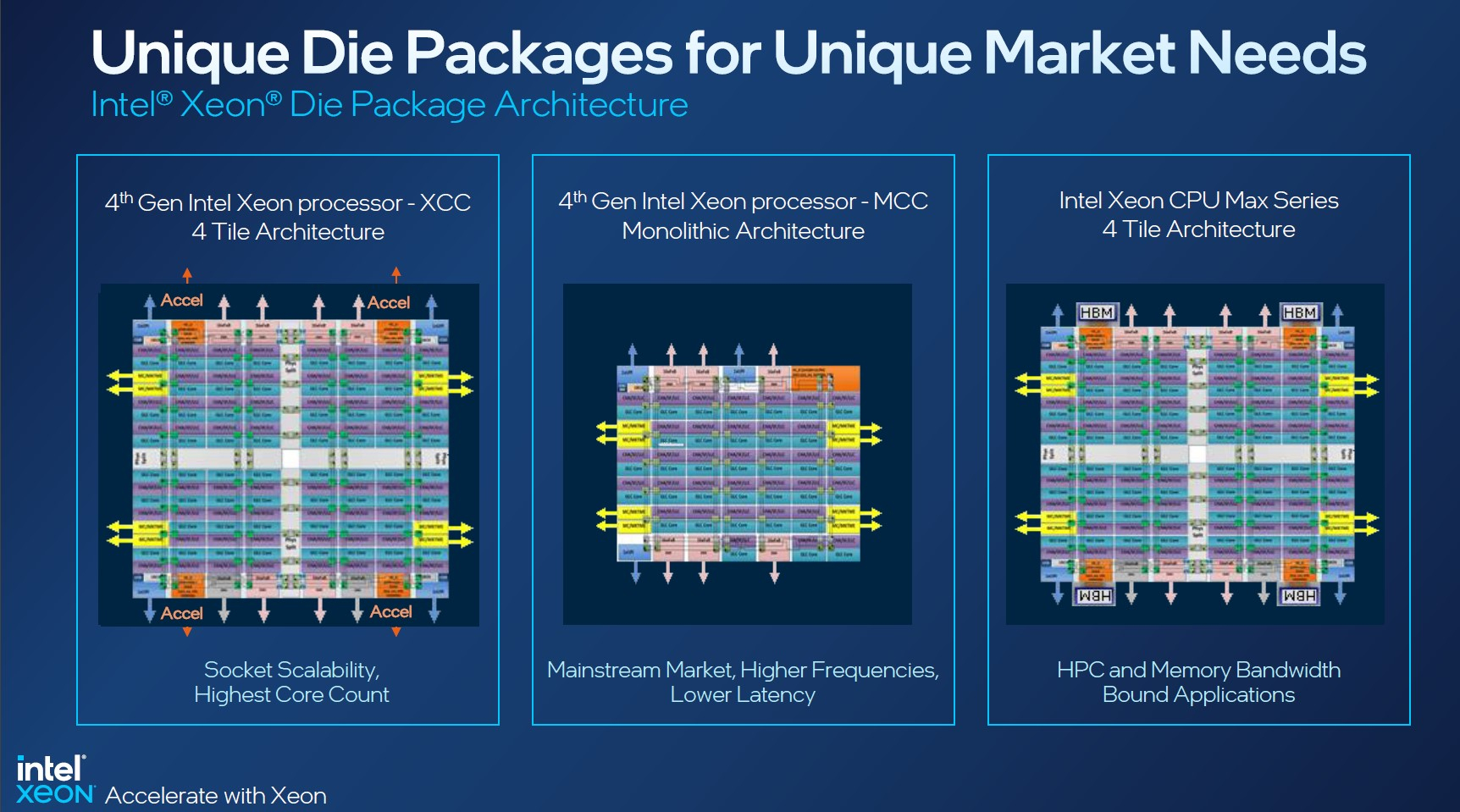 Сохранилось традиционное разделение на серии Platinum (8000), Gold (6000/5000), Silver (4000) и Bronze (3000), к которым теперь добавилась серия Max (9400). Список суффиксов, означающих оптимизацию под те или иные задачи и наличие каких-то особенностей, стал чуть шире: Y (SST-PP 2.0), Q (рассчитаны на работу с СЖО), U (односокетные общего назначения), T (увеличенный жизненный цикл), H (in-memory СУБД, аналитика, виртуализация), N (сетевые решения, в том числе для 5G), облачные P/V/M (IaaS/Paa/медиа), S (СХД и HCI). 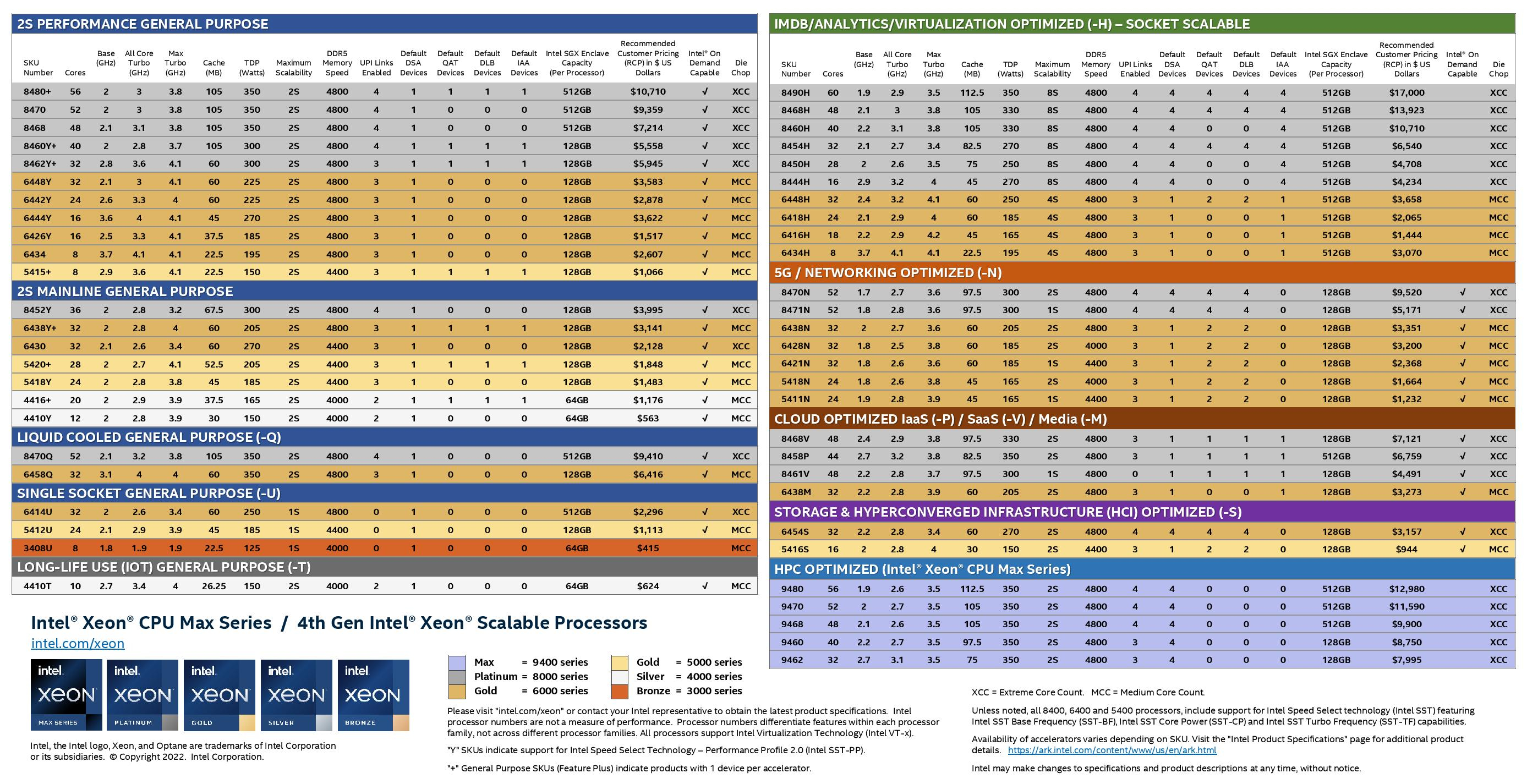 Но некоторые модели также имеют в названии «+». И вот тут начинается самое интересное! Все процессоры получили «традиционную» (в сравнении с Genoa) реализацию AVX-512, включая DL Boost, а также целый новый набор ИИ-инструкций AMX (до 10 раз быстрее обучение и инференс в сравнении с Ice Lake-SP). Есть и всяческие Speed Select, DDIO, TDX, CET и т.д. Но Sapphire Rapids также получили четыре отдельных ускорителя:
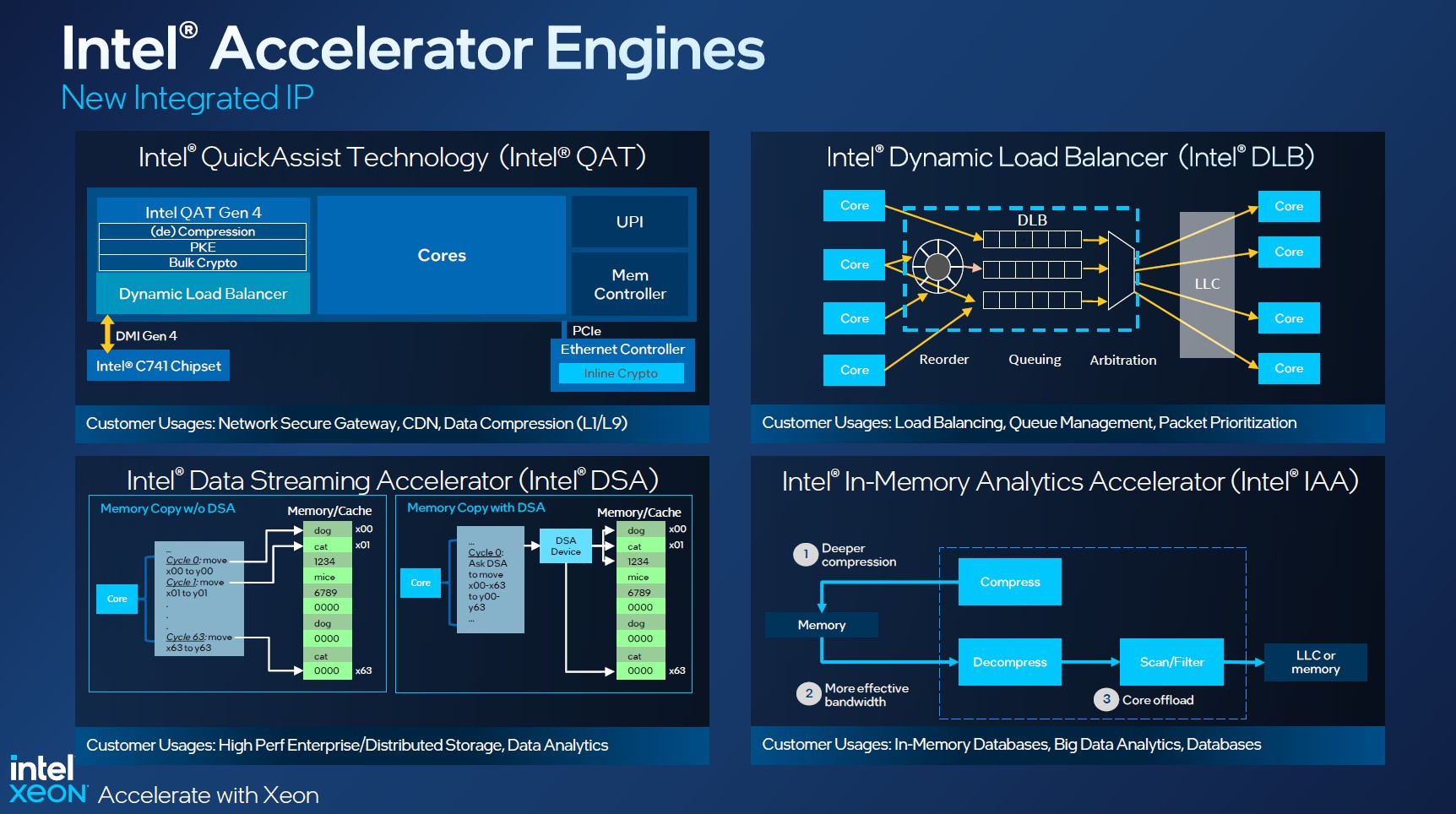 Intel заявляет, что средний прирост производительности Sapphire Rapids в сравнении с Ice Lake-SP составил 1,53 раза. А вот для ряда нагрузок, которые могут задействовать новые ускорители прирост производительности на Вт составляет уже до 2,9 раз! То есть Intel продолжает придерживаться стратегии создания максимально универсальных CPU для различных нагрузок. И действительно, спорить с гибкостью Sapphire Rapids трудно. Но какой ценой это достигается? Т.е. буквально: во сколько это обойдётся заказчику? Ответа пока нет.  Дело в том, что в зависимости от модели отличается число доступных и число активированных ускорителей. Фактически в новом поколении используется два вида кристаллов: XCC, «сшитые» из четырёх отдельных тайлов, и монолитные MCC (до 32 ядер, причём 32-ядерных моделей в серии большинство). У каждого тайла в XCC есть по одному блоку QAT, DSA, DLB и IAA, т.е. суммарно на CPU приходится до четырёх ускорителей каждого типа. В случае MCC может быть по два QAT и DLB и по одному DSA и IAA на процессор. Например, у тех моделей, что помечены «+», активно по одному блоку каждого типа, а минимум один DSA активен есть вообще у всех CPU.  За не активированные по умолчанию ускорители придётся заплатить в рамках программы Intel On Demand (SDSi), причём есть опции как с единовременным платежом за постоянную активацию, так и с оплатой по факту использования (это удобно в случае облаков и платформ по типу HPE Greenlake). Исключением являются H-модели, куда входит и самый дорогой ($17000) 60-ядерный процессор 8490H с полностью разблокированными ускорителями и поддержкой 8S-конфигураций, а также процессоры Max, которым доступно только четыре DSA-блока и 2S-платформы, например, 56-ядерный 9480 ($12980). 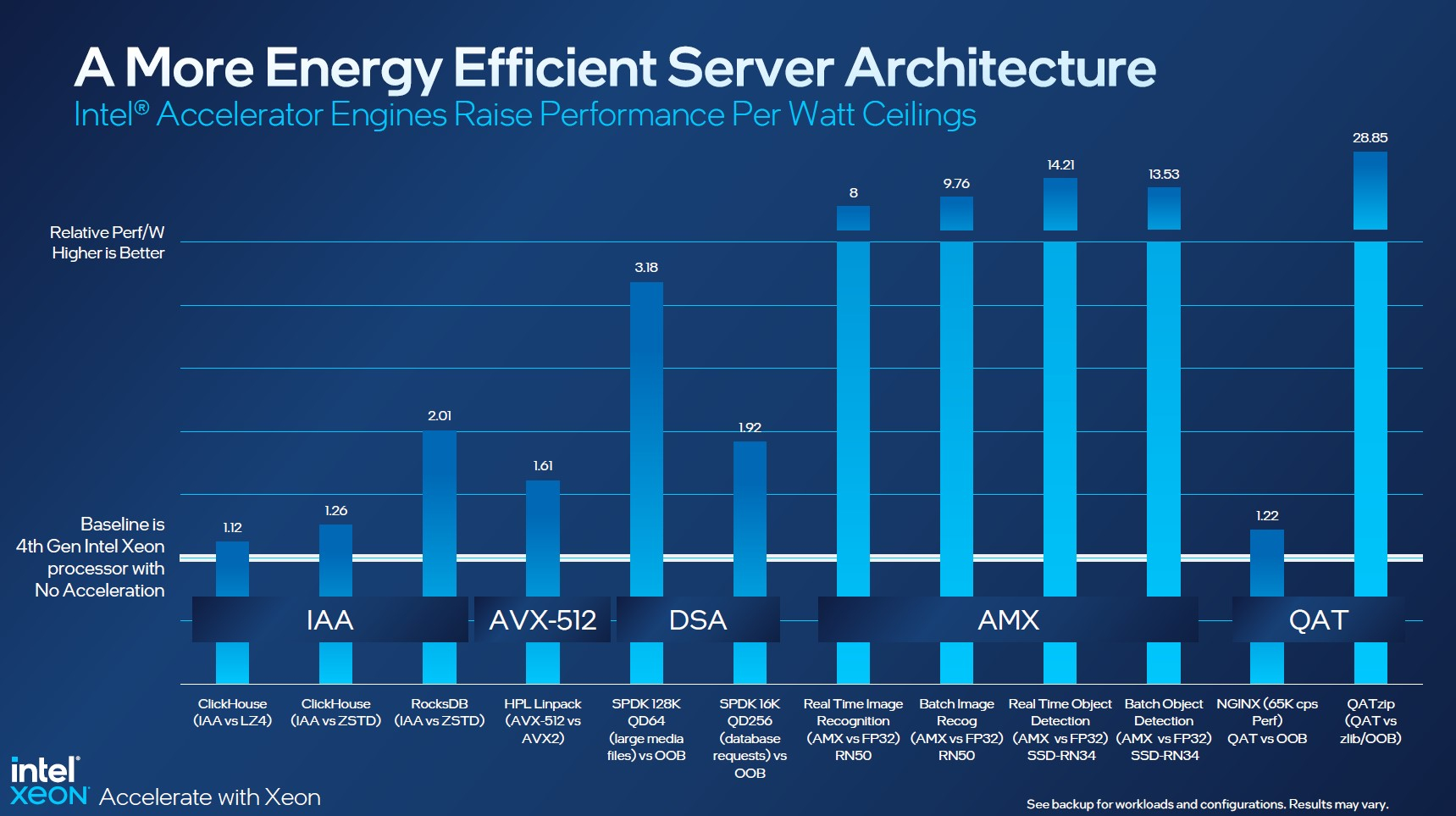 С одной стороны, желание Intel предоставить больше гибкости заказчикам, а заодно чуть увеличить выход годных к продаже процессоров, понятно. С другой — не очень-то и похоже, что CPU без «лишних» ускорителей отдаются с какой-то существенной скидкой. При этом транзисторный бюджет на них всё равно расходуется. Кроме того, есть ещё момент востребованности этих ускорителей и готовности ПО. У Intel есть и опыт ресурсы для помощи разработчикам, но процесс адаптации в любом случае не мгновенен.  Впрочем, у Intel по сравнению с AMD есть и ещё одно важное преимущество — в среднем более высокая доступность процессоров для большинства заказчиков. Так что с Sapphire Rapids может повториться та же история, что с Ice Lake-SP, когда вендоры здесь и сейчас готовы были предложить Intel-платформы.  В целом же, в новом семействе наиболее любопытны Xeon Max, которые, по словам Intel, по сравнению с прошлым поколением в 3,7 раз производительнее в задачах, завязанных на пропускную способность памяти (а это целый пласт HPC-нагрузок), и которые не так уж дороги. Правда, и здесь без приключений не обошлось — несчастный суперкомпьютер Aurora ожидает утомительный апгрейд его 10 тыс. узлов c простых Xeon Sapphire Rapids на Xeon Max — по полчаса на каждый узел. |
|

